Edge detection: The Scale Space Theory
Consider an image as a bounded function 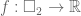

Initially, we may consider the process of detection of an edge by the simple computation of the gradient 


- The points where the gradient is larger than a given threshold are open sets, and thus don’t have the structure of curves.
- Large gradient may arise in certain locations of the image due to tiny oscillations or noise, but completely unrelated to the objects being mapped. As a matter of fact, there is no reason to assume the existence or computability of any gradient at all in a given digital image.
The second objection is solved by defining a smoothing process: We associate with the image a smoothed version 



The first objection is solved by defining edge points not as points where the gradient is large alone, but as points where some maximality property of the gradient is observed. Let us take an example in dimension one:
Let
be a
function and consider points where
is maximal. At these points, the second derivative might change sign. Thus, we can look for the “edge points” of the smooth signal among the points where
crosses zero.
Generalizing this idea in two dimensions leads to the Hildreth-Marr edge detection theory, or alternatively to the Canny edge detection theory. The only difference is that Hildreth and Marr replace, in dimension two, 


Canny instead, gives up the linearity of the Laplacian and defines edge points as points where the gradient is maximal in the direction of the gradient. This means that an edge point satisfies 

Note that this condition is equivalent to the simpler:

Let us proceed to code these two edge detection algorithms: In both cases, we start by convolving the image with Gaussians 

Hildreth-Marr
- At each scale
compute the zero-crossings of the Laplacian: those points
where
and
changes sign.
- Eliminate zero-crossings with small gradient.
Both gradient and Laplacian are easy to compute in sage:
from numpy import * import scipy.ndimage import scipy.signal image = scipy.misc.lena().astype(float32) # Convolve with a Gaussian Gt for t=2 [X,Y]=numpy.mgrid[-6:7,-6:7] A=X+i*Y R=abs(A) t=2.0 Gt=exp(-R*R/4.0/t)/4.0/pi/t convImage = scipy.signal.convolve(image,Gt) # Gradient Grdnt = numpy.gradient(convImage) # Magnitude of the gradient magn = sqrt( Grdnt[0]*Grdnt[0] + Grdnt[1]*Grdnt[1] ) # Laplacian Lplz = scipy.ndimage.laplace(float32(convImage))
 |
|
| Gradient (in blue) and perpendicular to the gradient (in red); detail from the center of the image | |
 |
 |
| Magnitude of the gradient (magn) | Laplacian of the image (Lplz) |
For the purposes of this post, we will consider that a pixel 
- Horizontal crossing:
- Vertical crossing:
- NW-SE crossing:
- NE-SW crossing:




A quick way to code a matrix that collects all the pixels where any of these crossings occur can be done as follows:
# Four matrices holding the crossings...
WWEE = zeros(Lplz.shape)
NNSS = zeros(Lplz.shape)
NWSE = zeros(Lplz.shape)
NESW = zeros(Lplz.shape)
WWEE[1:Lplz.shape[0]-1,:] = sign(multiply(Lplz[0:Lplz.shape[0]-2,:],
Lplz[2:Lplz.shape[0],:]))<0
NNSS[:,1:Lplz.shape[1]-1] = sign(multiply(Lplz[:,0:Lplz.shape[1]-2],
Lplz[:,2:Lplz.shape[1]]))<0
NWSE[1:Lplz.shape[0]-1,1:Lplz.shape[1]-1] =
sign(multiply(Lplz[0:Lplz.shape[0]-2,0:Lplz.shape[1]-2],
Lplz[2:Lplz.shape[0],2:Lplz.shape[1]]))<0
NESW[1:Lplz.shape[0]-1,1:Lplz.shape[1]-1] =
sign(multiply(Lplz[2:Lplz.shape[0],0:Lplz.shape[1]-2],
Lplz[0:Lplz.shape[0]-2,2:Lplz.shape[1]]))<0
# ...combined into a single matrix holding all the crossings
ZeroCrossings = maximum( maximum( maximum(NNSS, WWEE), NWSE), NESW)
It only remains to throw away those zero-crossings (below, left) where the magnitude of the gradient is small. I decided to set as threshold 
theta=3.0 Edges = multiply(ZeroCrossings, magn>theta)
 |
 |
| ZeroCrossings | Edges |
We need to repeat the same procedure on the smoothing 



Canny
- At each scale
and where the expression below changes sign:
- At each scale
and discard the points


We start by computing a matrix N where we collect, for each index 
D1,D2=numpy.gradient(convImage)
D11,D12=numpy.gradient(D1)
D21,D22=numpy.gradient(D2)
N = D1*D11*D1 + D1*D12*D2 + D2*D21*D1 + D2*D22*D2
WWEE[1:N.shape[0]-1,:] = sign(N[0:N.shape[0]-2,:]*N[2:N.shape[0],:])<0
NNSS[:,1:N.shape[1]-1] = sign(N[:,0:N.shape[1]-2]*N[:,2:N.shape[1]])<0
NWSE[1:N.shape[0]-1,1:N.shape[1]-1] =
sign(N[0:N.shape[0]-2,0:N.shape[1]-2]*
N[2:N.shape[0],2:N.shape[1]])<0
NESW[1:N.shape[0]-1,1:N.shape[1]-1] =
sign(N[2:N.shape[0],0:N.shape[1]-2]*
N[0:N.shape[0]-2,2:N.shape[1]])<0
ZeroCrossings = maximum( maximum( maximum(NNSS, WWEE), NWSE), NESW)
theta=3.0
Edges=multiply(ZeroCrossings, magn>theta)
 |
 |
| ZeroCrossings (Canny) | Edges (Canny) |
As in the algorithm of Hildreth-Marr, we need to repeat the same procedure on the smoothing 

Miscellaneous
The Scale Space Theory
What do we do with all different edge maps at different scales? For most images it is enough to “choose” the edge map at a certain scale—that one that visually satisfies whatever constraints we might require for a particular problem. Sometimes it pays off to collect them all, or start with the edges at the lowest level scale, and add a selection of the new edges from the larger scales… There is no single best method, as far as I am concerned.
Codes for graphics
The code that produced most of the images above is straightforward, except maybe the addition of the vector fields of the gradient and its normal on top of the windowed image. This was accomplished with the following commands:
matplotlib.pyplot.figure()
# Plot the Gradient (note the switching of derivatives and sign)
matplotlib.pyplot.quiver(-D2[300:450:4,300:450:4],D1[300:450:4,300:450:4],
color='b', pivot='mid', units='x')
# Plot the perpendicular to the Gradient
matplotlib.pyplot.quiver(D1[300:450:4,300:450:4],D2[300:450:4,300:450:4],
color='r', pivot='mid', units='x')
matplotlib.pyplot.quiver(-D1[300:450:4,300:450:4],-D2[300:450:4,300:450:4],
color='r', pivot='mid', units='x')
# Place the corresponding window of the image as background
matplotlib.pyplot.gray()
matplotlib.pyplot.imshow(float32(convImage[300:450:4,300:450:4]))
matplotlib.pyplot.savefig('/Users/blanco/Desktop/quiver.png')
Note that the first and second derivatives seem to have switched places. One needs to be very careful when dealing with matrices of numbers, since the logical position of the pixels depends very heavily the software/language/libraries that handles them. With sage this is a constant issue, especially since we might be using different (and unrelated) libraries to deal with the same objects.
References

Leave a comment
Blanco-Silva’s Books
Click on either image for more information


In the news:


 Math updates on arXiv.org
Math updates on arXiv.org
- On the image of the total power operation for Burnside rings
- A note on hidden classes in spinor classification
- Modularity of certain products of the Rogers-Ramanujan continued fraction
- Complex Analytic Structure of Stationary Flows of an Ideal Incompressible Fluid
- Learning the local density of states of a bilayer moir\'e material in one dimension
- Hypergeometric Distribution Revisited: Tail Inequalities, Confidence Bounds and Sample Sizes
- Positive formula for the product of conjugacy classes on the unitary group
- Neural Estimation Of Entropic Optimal Transport
- Some Homological Conjectures Over Idealization Rings
- On kernels of homological representations of mapping class groups
sagemath
- An error has occurred; the feed is probably down. Try again later.

in the second example why is the condition of the gradient equivalent to that other expression? I dont get it
Hi, thanks for your question. I assume you mean “why is equivalent to the identity below”, right?
is equivalent to the identity below”, right?
I’ll go ahead and answer that—by the way, I am assuming that you have knowledge of vector Calculus. First, notice that it is the same to find the critical points of as the critical points of
as the critical points of  , because
, because  is a square root of a non-negative expression. So I will work with the derivative of
is a square root of a non-negative expression. So I will work with the derivative of  instead, where
instead, where
Now, we can write The derivatives of
The derivatives of  and
and  are similar, so let me work one of them, and collect the result for both later on:
are similar, so let me work one of them, and collect the result for both later on:
This gives for the expression
the expression
A similar computation gives for the expression
the expression
Now, add both expressions, and collect them in matricial form. It looks like this:
which is what we wanted.