Naïve Bayes
There is nothing naïve about Naïve Bayes—a very basic, but extremely efficient data mining method to take decisions when a vast amount of data is available. The name comes from the fact that this is the simplest application to this problem, upon (the naïve) assumption of independence of the events. It is based on Bayes’ rule of conditional probability: If you have a hypothesis 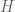
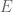

where as usual, 
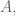


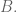
I would like to show an example of this technique, of course, with yet another decision-making algorithm oriented to guess my reaction to a movie I have not seen before. From the data obtained in a previous post, I create a simpler table with only those movies that have been scored more than 28 times (by a pool of 87 of the most popular critics featured in www.metacritics.com) [I posted the script to create that table at the end of the post]
Let’s test it:
>>> len(table)
49
>>> [entry[0] for entry in table]
[‘rabbit-hole’, ‘carnage-2011’, ‘star-wars-episode-iii—revenge-of-the-sith’,
‘shame’, ‘brokeback-mountain’, ‘drive’, ‘sideways’, ‘salt’,
‘million-dollar-baby’, ‘a-separation’, ‘dark-shadows’,
‘the-lord-of-the-rings-the-return-of-the-king’, ‘true-grit’, ‘inception’,
‘hereafter’, ‘master-and-commander-the-far-side-of-the-world’, ‘batman-begins’,
‘harry-potter-and-the-deathly-hallows-part-2’, ‘the-artist’, ‘the-fighter’,
‘larry-crowne’, ‘the-hunger-games’, ‘the-descendants’, ‘midnight-in-paris’,
‘moneyball’, ‘8-mile’, ‘the-departed’, ‘war-horse’,
‘the-lord-of-the-rings-the-fellowship-of-the-ring’, ‘j-edgar’,
‘the-kings-speech’, ‘super-8’, ‘robin-hood’, ‘american-splendor’, ‘hugo’,
‘eternal-sunshine-of-the-spotless-mind’, ‘the-lovely-bones’, ‘the-tree-of-life’,
‘the-pianist’, ‘the-ides-of-march’, ‘the-quiet-american’, ‘alexander’,
‘lost-in-translation’, ‘seabiscuit’, ‘catch-me-if-you-can’, ‘the-avengers-2012’,
‘the-social-network’, ‘closer’, ‘the-girl-with-the-dragon-tattoo-2011’]
>>> table[0]
[‘rabbit-hole’, ”, ‘B+’, ‘B’, ”, ‘C’, ‘C+’, ”, ‘F’, ‘B+’, ‘F’, ‘C’, ‘F’, ‘D’,
”, ”, ‘A’, ”, ”, ”, ”, ‘B+’, ‘C+’, ”, ”, ”, ”, ”, ”, ‘C+’, ”, ”,
”, ”, ”, ”, ‘A’, ”, ”, ”, ”, ”, ‘A’, ”, ”, ‘B+’, ‘B+’, ‘B’, ”, ”,
”, ‘D’, ‘B+’, ”, ”, ‘C+’, ”, ”, ”, ”, ”, ”, ‘B+’, ”, ”, ”, ”, ”,
”, ‘A’, ”, ”, ”, ”, ”, ”, ”, ‘D’, ”, ”,’C+’, ‘A’, ”, ”, ”, ‘C+’, ”]
Note the titles of the movies: I have only seen some of them, and I proceed to score those ones below, with the same grading scheme:
| 'star-wars-episode-iii---revenge-of-the-sith' | B |
| 'brokeback-mountain' | B |
| 'salt' | B |
| 'million-dollar-baby' | A |
| 'the-lord-of-the-rings-the-return-of-the-king' | C+ |
| 'true-grit' | B+ |
| 'inception' | A |
| 'batman-begins' | A |
| 'harry-potter-and-the-deathly-hallows-part-2' | D |
| 'the-fighter' | B+ |
| 'the-hunger-games' | C+ |
| 'the-descendants' | C+ |
| 'moneyball' | B+ |
| '8-mile' | B |
| 'war-horse' | B+ |
| 'the-lord-of-the-rings-the-fellowship-of-the-ring' | B |
| 'the-kings-speech' | B |
| 'super-8' | A |
| 'robin-hood' | B |
| 'eternal-sunshine-of-the-spotless-mind' | C+ |
| 'the-tree-of-life' | F |
| 'the-pianist' | B+ |
| 'lost-in-translation' | B+ |
| 'catch-me-if-you-can' | B |
| 'the-avengers-2012' | C+ |
| 'the-girl-with-the-dragon-tattoo-2011' | B+ |
I will call this list my “evidence” and denote it 

But the evidence

|

|

|
|

|
|

|
|

|
|

|
|

|
We need not to worry about the probability 

All the probabilities in the product on the right-hand side of the previous equation are computed from the table in an obvious way (by counting!) For instance, to compute 
[‘salt’, ‘A’, ‘C+’, ”, ‘C’, ‘F’, ‘C+’, ”, ”, ‘F’, ‘F’, ”, ‘B’, ‘B’, ‘B’, ”,
‘B’, ”, ”, ”, ”, ‘D’, ‘C+’, ”, ”, ‘C’, ”, ”, ”, ‘C+’, ”, ”, ”, ”,
”, ”, ‘F’, ”, ”, ”, ”, ‘D’, ‘C+’, ”, ”, ‘F’, ”, ‘F’, ”, ”, ”, ‘A’,
”, ”, ‘D+’, ‘F’, ‘D+’, ”, ‘D’, ”, ”, ”, ‘F’, ”, ”, ”, ”, ”, ”, ‘B’,
”, ”, ”, ”, ‘F’, ”, ”, ”, ”, ”, ”, ”, ”, ”, ”, ”, ”]
>>> table[34]
[‘hugo’, ‘A’, ‘B+’, ‘F’, ‘A’, ”, ”, ”, ‘F’, ”, ‘F’, ”, ”, ‘C’, ‘A’, ”, ‘A’,
‘A’, ”, ”, ”, ‘B+’, ‘C+’, ”, ”, ”, ‘A’, ”, ”, ‘C+’, ”, ”, ”, ”, ”,
”, ‘B’, ”, ”, ”, ”, ‘A’, ”, ”, ”, ‘B+’, ”, ‘B’, ‘A’, ”, ”, ”, ‘A’,
”, ‘A’, ”, ”, ”, ‘C+’, ”, ”, ”, ‘C+’, ”, ”, ”, ”, ”, ”, ‘A’, ”, ”,
”, ”, ‘D’, ‘A’, ‘A’, ”, ”, ”, ‘B+’, ”, ”, ”, ”, ”, ”]
>>> len([[table[7][i],table[34][i]] for i in range(len(table[7])) \
if table[7][i]==”B” and table[34][i]==”A”])
3
Of the 87 critics, only 3 granted 'salt' a B, while giving 'hugo' an A. This means that, according to this scheme, 
| 'salt'= | A | B+ | B | C+ | C | D+ | D | F | no-score | TOTAL |
| 'hugo'=A | 1 | 0 | 3 | 0 | 1 | 1 | 1 | 0 | 6 | 13 |
Note that an occurrence of a zero in one of these probabilities makes our algorithm go “boom.” To solve this issue, we apply a Laplace estimator: We always add one to the numerators of the probabilities, and compensate adding as much as necessary in the denominators. In this case, since we have 9 different classes (A, B+, B, C+, C, D+, D, F and no-score) we add nine to the denominators. We would have then

Similarly, for the prior probability (the one in which we don’t know any piece of evidence) we have 
This is now a fully Bayesian formulation where prior probabilities have been assigned to everything in sight. It is completely rigorous, albeit the fact that, indeed, in our case independence might not be guaranteed.
At this point, I leave as an exercise the coding of this algorithm. According to this scheme, what will be the score for the movie 'hugo' with the highest probability? This is what this data mining idea implies I would think after seeing it. Also, how do the results of this algorithm compare to those of my weighted averages?
Python Script to create a table with all movies with at least N scores
# retrieve the data:
# the list critics with the names of the critics, and
# the corresponding list scoredMovies with dicts.
# Each dict in position j contains as keys the names of the movies scored
# and their scores by the featured critic in position j from the critics
# list
from movieData import *
# This is how to create a list with all the different movies scored
def collectMovies(scoredMovies):
allMovies=set()
for movies in scoredMovies:
allMovies = allMovies | set(movies.keys())
return list(allMovies)
# The following function retrieves all movies with at least N scores
def moviesWithMoreThanNScores(scoredMovies,N):
allMovies = collectMovies(scoredMovies)
truefalseMovieHelper = map( lambda movie: map(lambda criticWork:
criticWork.has_key(movie),scoredMovies), allMovies)
movieCount = map( lambda x:x.count(True), truefalseMovieHelper)
return [movie for index,movie in enumerate(allMovies) if movieCount[index]>=N]
# prepTable gives us a table with those movies with at least N scores,
# together with those scores (87 in total). If the critic in position "j"
# happened not to score a movie, the corresponding "j" entry for that movie
# is an empty string. Note that we turn numerical values into grades
# (A, B+, B, C+, C, D+, D and F)
def prepTable(scoredMovies,N):
def transformScore(criticScore,movie):
if movie in criticScore.keys():
score = criticScore[movie]
if score<60:
return "F"
elif score<65:
return "D"
elif score<70:
return "D+"
elif score<75:
return "C"
elif score<80:
return "C+"
elif score<85:
return "B"
elif score<90:
return "B+"
else: return "A"
else: return ""
tableMovies = moviesWithMoreThanNScores(scoredMovies,N)
table = []
for movie in tableMovies:
row=[movie]
for criticScore in scoredMovies:
row.append(transformScore(criticScore,movie))
table.append(row)
return table

Blanco-Silva’s Books
Click on either image for more information


In the news:


 Math updates on arXiv.org
Math updates on arXiv.org
- On the image of the total power operation for Burnside rings
- A note on hidden classes in spinor classification
- Modularity of certain products of the Rogers-Ramanujan continued fraction
- Complex Analytic Structure of Stationary Flows of an Ideal Incompressible Fluid
- Learning the local density of states of a bilayer moir\'e material in one dimension
- Hypergeometric Distribution Revisited: Tail Inequalities, Confidence Bounds and Sample Sizes
- Positive formula for the product of conjugacy classes on the unitary group
- Neural Estimation Of Entropic Optimal Transport
- Some Homological Conjectures Over Idealization Rings
- On kernels of homological representations of mapping class groups
sagemath
- An error has occurred; the feed is probably down. Try again later.
