Archive
Stones, balances, matrices

Let’s examine an easy puzzle on finding the different stone by using a balance:
You have four stones identical in size and appearance, but one of them is heavier than the rest. You have a set of scales (a balance): how many weights do you need to determine which stone is the heaviest?
This is a trivial problem, but I will use it to illustrate different ideas, definitions, and the connection to linear algebra needed to answer the harder puzzles below. Let us start by solving it in the most natural way:
- Enumerate each stone from 1 to 4.
- Set stones 1 and 2 on the left plate; set stones 3 and 4 on the right plate. Since one of the stones is heavier, it will be in the plate that tips the balance. Let us assume this is the left plate.
- Discard stones 3 and 4. Put stone 1 on the left plate; and stone 2 on the right plate. The plate that tips the balance holds the heaviest stone.
This solution finds the stone in two weights. It is what we call adaptive measures: each measure is determined by the result of the previous. This is a good point to introduce an algebraic scheme to code the solution.
- The weights matrix: This is a matrix with four columns (one for each stone) and two rows (one for each weight). The entries of this matrix can only be
or
depending whether a given stone is placed on the left plate
, on the right plate
or in neither plate
For example, for the solution given above, the corresponding matrix would be
- The stones matrix: This is a square matrix with four rows and columns (one for each stone). Each column represents a different combination of stones, in such a way that the n-th column assumes that the heaviest stone is in the n-th position. The entries on this matrix indicate the weight of each stone. For example, if we assume that the heaviest stone weights b units, and each other stone weights a units, then the corresponding stones matrix is


Multiplying these two matrices, and looking at the sign of the entries of the resulting matrix, offers great insight on the result of the measures:

Note the columns of this matrix code the behavior of the measures:
- The column
indicates that the balance tipped to the left in both measures (and therefore, the heaviest stone is the first one)
- The column
indicates that the heaviest stone is the second one.
- Note that the other two measures can’t find the heaviest stone, since this matrix was designed to find adaptively a stone supposed to be either the first or the second.
Is it possible to design a solution to this puzzle that is not adaptive? Note the solution with two measures given (in algebraic form) below:
![\text{sign} \left[ \begin{pmatrix} 1 & 1 & -1 & -1 \\ 1 & -1 & 1 & -1 \end{pmatrix} \cdot B \right] = \begin{pmatrix} + & + & - & - \\ + & - & + & - \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Ctext%7Bsign%7D+%5Cleft%5B+%5Cbegin%7Bpmatrix%7D+1+%26+1+%26+-1+%26+-1+%5C%5C+1+%26+-1+%26+1+%26+-1+%5Cend%7Bpmatrix%7D+%5Ccdot+B+%5Cright%5D+%3D+%5Cbegin%7Bpmatrix%7D+%2B+%26+%2B+%26+-+%26+-+%5C%5C+%2B+%26+-+%26+%2B+%26+-+%5Cend%7Bpmatrix%7D&bg=ffffff&fg=555555&s=0&c=20201002)
Since each column is different, it is trivial to decide after the experiment is done, which stone will be the heaviest. For instance, if the balance tips first to the right (-) and then to the left (+), the heaviest stone can only be the third one.
Let us make it a big harder: Same situation, but now we don’t know whether the stone that is different is heavier or lighter.
The solution above is no good: Since we are not sure whether b is greater or smaller than a, we would obtain two sign matrices which are virtually mirror images of each other.
 and
and 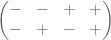
In this case, in the event of obtaining that the balance tips twice to the left: which would be the different stone? The first, which is heaviest, or the fourth, which is lightest? We cannot decide.
One possible solution to this situation involves taking one more measure. Look at the algebraic expression of the following example, to realize why:
![\text{sign} \left[ \begin{pmatrix} 1 & 1 & -1 & -1 \\ 1 & -1 & 1 & -1 \\ 1 & -1 & -1 & 1 \end{pmatrix} \cdot B \right] = \begin{pmatrix} + & + & - & - \\ + & - & + & - \\ + & - & - & + \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Ctext%7Bsign%7D+%5Cleft%5B+%5Cbegin%7Bpmatrix%7D+1+%26+1+%26+-1+%26+-1+%5C%5C+1+%26+-1+%26+1+%26+-1+%5C%5C+1+%26+-1+%26+-1+%26+1+%5Cend%7Bpmatrix%7D+%5Ccdot+B+%5Cright%5D+%3D+%5Cbegin%7Bpmatrix%7D+%2B+%26+%2B+%26+-+%26+-+%5C%5C+%2B+%26+-+%26+%2B+%26+-+%5C%5C+%2B+%26+-+%26+-+%26+%2B+%5Cend%7Bpmatrix%7D&bg=ffffff&fg=555555&s=0&c=20201002) or
or 
In this case there is no room for confusion: if the balance tips three times to the same side, then the different stone is the first one (whether heavier or lighter). The other possibilities are also easily solvable: if the balance tips first to one side, then to the other, and then to the first side, then the different stone is the third one.
The reader will not be very surprised at this point to realize that three (non adaptive) measures are also enough to decide which stone is different (be it heavier or lighter) in a set of twelve similar stones. To design the solution, a good weight matrix with twelve columns and three rows need to be constructed. The trick here is to allow measures that balance both plates, which gives us more combinations with which to play. How would the reader design this matrix?
Naïve Bayes
There is nothing naïve about Naïve Bayes—a very basic, but extremely efficient data mining method to take decisions when a vast amount of data is available. The name comes from the fact that this is the simplest application to this problem, upon (the naïve) assumption of independence of the events. It is based on Bayes’ rule of conditional probability: If you have a hypothesis 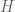
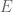

where as usual, 
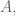


I would like to show an example of this technique, of course, with yet another decision-making algorithm oriented to guess my reaction to a movie I have not seen before. From the data obtained in a previous post, I create a simpler table with only those movies that have been scored more than 28 times (by a pool of 87 of the most popular critics featured in www.metacritics.com) [I posted the script to create that table at the end of the post]
Let’s test it:
>>> len(table)
49
>>> [entry[0] for entry in table]
[‘rabbit-hole’, ‘carnage-2011’, ‘star-wars-episode-iii—revenge-of-the-sith’,
‘shame’, ‘brokeback-mountain’, ‘drive’, ‘sideways’, ‘salt’,
‘million-dollar-baby’, ‘a-separation’, ‘dark-shadows’,
‘the-lord-of-the-rings-the-return-of-the-king’, ‘true-grit’, ‘inception’,
‘hereafter’, ‘master-and-commander-the-far-side-of-the-world’, ‘batman-begins’,
‘harry-potter-and-the-deathly-hallows-part-2’, ‘the-artist’, ‘the-fighter’,
‘larry-crowne’, ‘the-hunger-games’, ‘the-descendants’, ‘midnight-in-paris’,
‘moneyball’, ‘8-mile’, ‘the-departed’, ‘war-horse’,
‘the-lord-of-the-rings-the-fellowship-of-the-ring’, ‘j-edgar’,
‘the-kings-speech’, ‘super-8’, ‘robin-hood’, ‘american-splendor’, ‘hugo’,
‘eternal-sunshine-of-the-spotless-mind’, ‘the-lovely-bones’, ‘the-tree-of-life’,
‘the-pianist’, ‘the-ides-of-march’, ‘the-quiet-american’, ‘alexander’,
‘lost-in-translation’, ‘seabiscuit’, ‘catch-me-if-you-can’, ‘the-avengers-2012’,
‘the-social-network’, ‘closer’, ‘the-girl-with-the-dragon-tattoo-2011’]
>>> table[0]
[‘rabbit-hole’, ”, ‘B+’, ‘B’, ”, ‘C’, ‘C+’, ”, ‘F’, ‘B+’, ‘F’, ‘C’, ‘F’, ‘D’,
”, ”, ‘A’, ”, ”, ”, ”, ‘B+’, ‘C+’, ”, ”, ”, ”, ”, ”, ‘C+’, ”, ”,
”, ”, ”, ”, ‘A’, ”, ”, ”, ”, ”, ‘A’, ”, ”, ‘B+’, ‘B+’, ‘B’, ”, ”,
”, ‘D’, ‘B+’, ”, ”, ‘C+’, ”, ”, ”, ”, ”, ”, ‘B+’, ”, ”, ”, ”, ”,
”, ‘A’, ”, ”, ”, ”, ”, ”, ”, ‘D’, ”, ”,’C+’, ‘A’, ”, ”, ”, ‘C+’, ”]
Blanco-Silva’s Books
Click on either image for more information


In the news:


 Math updates on arXiv.org
Math updates on arXiv.org
- On the image of the total power operation for Burnside rings
- A note on hidden classes in spinor classification
- Modularity of certain products of the Rogers-Ramanujan continued fraction
- Complex Analytic Structure of Stationary Flows of an Ideal Incompressible Fluid
- Learning the local density of states of a bilayer moir\'e material in one dimension
- Hypergeometric Distribution Revisited: Tail Inequalities, Confidence Bounds and Sample Sizes
- Positive formula for the product of conjugacy classes on the unitary group
- Neural Estimation Of Entropic Optimal Transport
- Some Homological Conjectures Over Idealization Rings
- On kernels of homological representations of mapping class groups
sagemath
- An error has occurred; the feed is probably down. Try again later.
