Archive
Searching (again!?) for the SS Central America

On Tuesday, September 8th 1857, the steamboat SS Central America left Havana at 9 AM for New York, carrying about 600 passengers and crew members. Inside of this vessel, there was stowed a very precious cargo: a set of manuscripts by John James Audubon, and three tons of gold bars and coins. The manuscripts documented an expedition through the yet uncharted southwestern United States and California, and contained 200 sketches and paintings of its wildlife. The gold, fruit of many years of prospecting and mining during the California Gold Rush, was meant to start anew the lives of many of the passengers aboard.
On the 9th, the vessel ran into a storm which developed into a hurricane. The steamboat endured four hard days at sea, and by Saturday morning the ship was doomed. The captain arranged to have women and children taken off to the brig Marine, which offered them assistance at about noon. In spite of the efforts of the remaining crew and passengers to save the ship, the inevitable happened at about 8 PM that same day. The wreck claimed the lives of 425 men, and carried the valuable cargo to the bottom of the sea.
It was not until late 1980s that technology allowed recovery of shipwrecks at deep sea. But no technology would be of any help without an accurate location of the site. In the following paragraphs we would like to illustrate the power of the scipy stack by performing a simple simulation, that ultimately creates a dataset of possible locations for the wreck of the SS Central America, and mines the data to attempt to pinpoint the most probable target.
We simulate several possible paths of the steamboat (say 10,000 randomly generated possibilities), between 7:00 AM on Saturday, and 13 hours later, at 8:00 pm on Sunday. At 7:00 AM on that Saturday the ship’s captain, William Herndon, took a celestial fix and verbally relayed the position to the schooner El Dorado. The fix was 31º25′ North, 77º10′ West. Because the ship was not operative at that point—no engine, no sails—, for the next thirteen hours its course was solely subjected to the effect of ocean current and winds. With enough information, it is possible to model the drift and leeway on different possible paths.
Book presentation at the USC Python Users Group
Have a child, plant a tree, write a book

Or more importantly: rear your children to become nice people, water those trees, and make sure that your books make a good impact.
I recently enjoyed the rare pleasure of having a child (my first!) and publishing a book almost at the same time. Since this post belongs in my professional blog, I will exclusively comment on the latter: Learning SciPy for Numerical and Scientific Computing, published by Packt in a series of technical books focusing on Open Source software.
Keep in mind that the book is for a very specialized audience: not only do you need a basic knowledge of Python, but also a somewhat advanced command of mathematics/physics, and an interest in engineering or scientific applications. This is an excerpt of the detailed description of the monograph, as it reads in the publisher’s page:
It is essential to incorporate workflow data and code from various sources in order to create fast and effective algorithms to solve complex problems in science and engineering. Data is coming at us faster, dirtier, and at an ever increasing rate. There is no need to employ difficult-to-maintain code, or expensive mathematical engines to solve your numerical computations anymore. SciPy guarantees fast, accurate, and easy-to-code solutions to your numerical and scientific computing applications.
Learning SciPy for Numerical and Scientific Computing unveils secrets to some of the most critical mathematical and scientific computing problems and will play an instrumental role in supporting your research. The book will teach you how to quickly and efficiently use different modules and routines from the SciPy library to cover the vast scope of numerical mathematics with its simplistic practical approach that is easy to follow.
The book starts with a brief description of the SciPy libraries, showing practical demonstrations for acquiring and installing them on your system. This is followed by the second chapter which is a fun and fast-paced primer to array creation, manipulation, and problem-solving based on these techniques.
The rest of the chapters describe the use of all different modules and routines from the SciPy libraries, through the scope of different branches of numerical mathematics. Each big field is represented: numerical analysis, linear algebra, statistics, signal processing, and computational geometry. And for each of these fields all possibilities are illustrated with clear syntax, and plenty of examples. The book then presents combinations of all these techniques to the solution of research problems in real-life scenarios for different sciences or engineering — from image compression, biological classification of species, control theory, design of wings, to structural analysis of oxides.
The book is also being sold online in Amazon, where it has been received with pretty good reviews. I have found other random reviews elsewhere, with similar welcoming comments:
- Artificial Intelligence in Motion by Marcel Caraciolo
- The Endeavour, by John D. Cook
Which one is the fake?

|

|

|
“Crab on its back” | “Willows at sunset” | “Still life: Potatoes in a yellow dish” |
Stones, balances, matrices

Let’s examine an easy puzzle on finding the different stone by using a balance:
You have four stones identical in size and appearance, but one of them is heavier than the rest. You have a set of scales (a balance): how many weights do you need to determine which stone is the heaviest?
This is a trivial problem, but I will use it to illustrate different ideas, definitions, and the connection to linear algebra needed to answer the harder puzzles below. Let us start by solving it in the most natural way:
- Enumerate each stone from 1 to 4.
- Set stones 1 and 2 on the left plate; set stones 3 and 4 on the right plate. Since one of the stones is heavier, it will be in the plate that tips the balance. Let us assume this is the left plate.
- Discard stones 3 and 4. Put stone 1 on the left plate; and stone 2 on the right plate. The plate that tips the balance holds the heaviest stone.
This solution finds the stone in two weights. It is what we call adaptive measures: each measure is determined by the result of the previous. This is a good point to introduce an algebraic scheme to code the solution.
- The weights matrix: This is a matrix with four columns (one for each stone) and two rows (one for each weight). The entries of this matrix can only be
or
depending whether a given stone is placed on the left plate
, on the right plate
or in neither plate
For example, for the solution given above, the corresponding matrix would be
- The stones matrix: This is a square matrix with four rows and columns (one for each stone). Each column represents a different combination of stones, in such a way that the n-th column assumes that the heaviest stone is in the n-th position. The entries on this matrix indicate the weight of each stone. For example, if we assume that the heaviest stone weights b units, and each other stone weights a units, then the corresponding stones matrix is


Multiplying these two matrices, and looking at the sign of the entries of the resulting matrix, offers great insight on the result of the measures:

Note the columns of this matrix code the behavior of the measures:
- The column
indicates that the balance tipped to the left in both measures (and therefore, the heaviest stone is the first one)
- The column
indicates that the heaviest stone is the second one.
- Note that the other two measures can’t find the heaviest stone, since this matrix was designed to find adaptively a stone supposed to be either the first or the second.
Is it possible to design a solution to this puzzle that is not adaptive? Note the solution with two measures given (in algebraic form) below:
![\text{sign} \left[ \begin{pmatrix} 1 & 1 & -1 & -1 \\ 1 & -1 & 1 & -1 \end{pmatrix} \cdot B \right] = \begin{pmatrix} + & + & - & - \\ + & - & + & - \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Ctext%7Bsign%7D+%5Cleft%5B+%5Cbegin%7Bpmatrix%7D+1+%26+1+%26+-1+%26+-1+%5C%5C+1+%26+-1+%26+1+%26+-1+%5Cend%7Bpmatrix%7D+%5Ccdot+B+%5Cright%5D+%3D+%5Cbegin%7Bpmatrix%7D+%2B+%26+%2B+%26+-+%26+-+%5C%5C+%2B+%26+-+%26+%2B+%26+-+%5Cend%7Bpmatrix%7D&bg=ffffff&fg=555555&s=0&c=20201002)
Since each column is different, it is trivial to decide after the experiment is done, which stone will be the heaviest. For instance, if the balance tips first to the right (-) and then to the left (+), the heaviest stone can only be the third one.
Let us make it a big harder: Same situation, but now we don’t know whether the stone that is different is heavier or lighter.
The solution above is no good: Since we are not sure whether b is greater or smaller than a, we would obtain two sign matrices which are virtually mirror images of each other.
 and
and 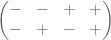
In this case, in the event of obtaining that the balance tips twice to the left: which would be the different stone? The first, which is heaviest, or the fourth, which is lightest? We cannot decide.
One possible solution to this situation involves taking one more measure. Look at the algebraic expression of the following example, to realize why:
![\text{sign} \left[ \begin{pmatrix} 1 & 1 & -1 & -1 \\ 1 & -1 & 1 & -1 \\ 1 & -1 & -1 & 1 \end{pmatrix} \cdot B \right] = \begin{pmatrix} + & + & - & - \\ + & - & + & - \\ + & - & - & + \end{pmatrix}](https://s0.wp.com/latex.php?latex=%5Ctext%7Bsign%7D+%5Cleft%5B+%5Cbegin%7Bpmatrix%7D+1+%26+1+%26+-1+%26+-1+%5C%5C+1+%26+-1+%26+1+%26+-1+%5C%5C+1+%26+-1+%26+-1+%26+1+%5Cend%7Bpmatrix%7D+%5Ccdot+B+%5Cright%5D+%3D+%5Cbegin%7Bpmatrix%7D+%2B+%26+%2B+%26+-+%26+-+%5C%5C+%2B+%26+-+%26+%2B+%26+-+%5C%5C+%2B+%26+-+%26+-+%26+%2B+%5Cend%7Bpmatrix%7D&bg=ffffff&fg=555555&s=0&c=20201002) or
or 
In this case there is no room for confusion: if the balance tips three times to the same side, then the different stone is the first one (whether heavier or lighter). The other possibilities are also easily solvable: if the balance tips first to one side, then to the other, and then to the first side, then the different stone is the third one.
The reader will not be very surprised at this point to realize that three (non adaptive) measures are also enough to decide which stone is different (be it heavier or lighter) in a set of twelve similar stones. To design the solution, a good weight matrix with twelve columns and three rows need to be constructed. The trick here is to allow measures that balance both plates, which gives us more combinations with which to play. How would the reader design this matrix?
Naïve Bayes
There is nothing naïve about Naïve Bayes—a very basic, but extremely efficient data mining method to take decisions when a vast amount of data is available. The name comes from the fact that this is the simplest application to this problem, upon (the naïve) assumption of independence of the events. It is based on Bayes’ rule of conditional probability: If you have a hypothesis 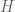
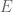

where as usual, 
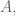


I would like to show an example of this technique, of course, with yet another decision-making algorithm oriented to guess my reaction to a movie I have not seen before. From the data obtained in a previous post, I create a simpler table with only those movies that have been scored more than 28 times (by a pool of 87 of the most popular critics featured in www.metacritics.com) [I posted the script to create that table at the end of the post]
Let’s test it:
>>> len(table)
49
>>> [entry[0] for entry in table]
[‘rabbit-hole’, ‘carnage-2011’, ‘star-wars-episode-iii—revenge-of-the-sith’,
‘shame’, ‘brokeback-mountain’, ‘drive’, ‘sideways’, ‘salt’,
‘million-dollar-baby’, ‘a-separation’, ‘dark-shadows’,
‘the-lord-of-the-rings-the-return-of-the-king’, ‘true-grit’, ‘inception’,
‘hereafter’, ‘master-and-commander-the-far-side-of-the-world’, ‘batman-begins’,
‘harry-potter-and-the-deathly-hallows-part-2’, ‘the-artist’, ‘the-fighter’,
‘larry-crowne’, ‘the-hunger-games’, ‘the-descendants’, ‘midnight-in-paris’,
‘moneyball’, ‘8-mile’, ‘the-departed’, ‘war-horse’,
‘the-lord-of-the-rings-the-fellowship-of-the-ring’, ‘j-edgar’,
‘the-kings-speech’, ‘super-8’, ‘robin-hood’, ‘american-splendor’, ‘hugo’,
‘eternal-sunshine-of-the-spotless-mind’, ‘the-lovely-bones’, ‘the-tree-of-life’,
‘the-pianist’, ‘the-ides-of-march’, ‘the-quiet-american’, ‘alexander’,
‘lost-in-translation’, ‘seabiscuit’, ‘catch-me-if-you-can’, ‘the-avengers-2012’,
‘the-social-network’, ‘closer’, ‘the-girl-with-the-dragon-tattoo-2011’]
>>> table[0]
[‘rabbit-hole’, ”, ‘B+’, ‘B’, ”, ‘C’, ‘C+’, ”, ‘F’, ‘B+’, ‘F’, ‘C’, ‘F’, ‘D’,
”, ”, ‘A’, ”, ”, ”, ”, ‘B+’, ‘C+’, ”, ”, ”, ”, ”, ”, ‘C+’, ”, ”,
”, ”, ”, ”, ‘A’, ”, ”, ”, ”, ”, ‘A’, ”, ”, ‘B+’, ‘B+’, ‘B’, ”, ”,
”, ‘D’, ‘B+’, ”, ”, ‘C+’, ”, ”, ”, ”, ”, ”, ‘B+’, ”, ”, ”, ”, ”,
”, ‘A’, ”, ”, ”, ”, ”, ”, ”, ‘D’, ”, ”,’C+’, ‘A’, ”, ”, ”, ‘C+’, ”]
Sometimes Math is not the answer
 I would love to stand corrected in this case, though. Let me explain first the reason behind this claim—It will take a minute, so bear with me:
I would love to stand corrected in this case, though. Let me explain first the reason behind this claim—It will take a minute, so bear with me:
Say there is a new movie released, and you would like to know how good it is, or whether you and your partner will enjoy watching it together. There are plenty of online resources out there that will give you enough information to make an educated opinion but, let’s face it, you will not have the complete picture unless you actually go see the movie (sorry for the pun).
For example, I fell for “The Blair Witch Project:” their amazing advertising campaign promised me thrill and originality. On top of that, the averaged evaluation of many movie critics that had access to previews claimed that this was a flick not to be missed… Heck, I even bought the DVD for my sister before even watching it!—She and I have a similar taste with respect to movies. The disappointment was, obviously, epic. Before that, and many a time afterwards, I have tripped over the same stone. If nothing else, I learned not to trust commercials and sneak previews any more (“Release the Kraken!
,” anyone?)
The only remaining resource should then be the advice of the knowledgeable movie critics—provided you trust on their integrity, that is. Then it hit me: My taste in movies, so similar to my sister’s, could be completely different to that of the “average critic”. Being that the case, why would I trust what a bunch of experts have to say? The mathematician in me took over, and started planning a potential algorithm:
Blanco-Silva’s Books
Click on either image for more information


In the news:


 Math updates on arXiv.org
Math updates on arXiv.org
- On the image of the total power operation for Burnside rings
- A note on hidden classes in spinor classification
- Modularity of certain products of the Rogers-Ramanujan continued fraction
- Complex Analytic Structure of Stationary Flows of an Ideal Incompressible Fluid
- Learning the local density of states of a bilayer moir\'e material in one dimension
- Hypergeometric Distribution Revisited: Tail Inequalities, Confidence Bounds and Sample Sizes
- Positive formula for the product of conjugacy classes on the unitary group
- Neural Estimation Of Entropic Optimal Transport
- Some Homological Conjectures Over Idealization Rings
- On kernels of homological representations of mapping class groups
sagemath
- An error has occurred; the feed is probably down. Try again later.
